 Interactive Worksheets
Interactive Worksheets Worksheets by Grade
Worksheets by Grade Number Sense and Operations
Number Sense and Operations Measurement
Measurement Statistics and Data
Statistics and Data Geometry
Geometry Pre-Algebra
Pre-Algebra Algebra
Algebra
Making Ten Worksheets
- Math >
- Number Sense >
- Addition >
- Making Ten
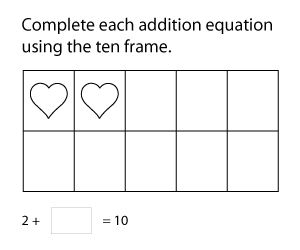
Equip kids with making ten worksheets featuring exercises to use number lines and ten frames to make 10, decompose numbers to create the friendly 10, and solve word problems using the making ten addition strategy. Drive home that 3 and 7, 4 and 6, 2 and 8, 5 and 5, 9 and 1 will all make a 10. The key takeaway of these PDF resources is determining the correct number combinations that add up to 10 to simplify addition. Use our answer keys for instant evaluations. Our free worksheets are a must-try!











Exclusive Making Ten Worksheets for Premium Members
Decomposing and Composing to Make 10
Split up the highlighted number into two addends. Find one addend that can be composed with the third addend to make a ten and find the sum effortlessly in these printables.

Word Problems with Making Strategy
Raise the bar using these making ten worksheets that provide real-life scenarios where kids can apply the making ten addition strategy to simplify addition.


Addition within 20 Using the Making 10 Strategy
Three addends come together to test your skills in these practice sheets. Look for the two addends that combine to make a 10, then add the third addend to find the sum effortlessly!

Recapitulate the making ten strategy with exercises like drawing hops on number lines, drawing shapes on ten frames, and decomposing to complete addition equations.

Composing and Decomposing | Revision
Assess skills with these making ten worksheets that comprise a mix of problems to compose and decompose addends, and find the possible ways to add two numbers using the making ten strategy.
